Apache Kafka: 15개의 글
 Kafka - Kafka(카프카)의 동작 방식과 원리
Kafka - Kafka(카프카)의 동작 방식과 원리
Kafka - Kafka(카프카)의 동작 방식과 원리 Kafka는 기본적으로 메시징 서버로 동작합니다. 여기서 메시징 시스템에 대해 간단히 살펴보자면 메시지라고 불리는 데이터 단위를 보내는 측(publisher,producer)에서 카프카에 토픽이라는 각각의 메시지 저장소에 데이터를 저장하면, 가져가는 측(subscriber, consumer)이 원하는 토픽에서 데이터를 가져가게 되어 있습니다. 즉, 메시지 시스템은 중앙에 메시징 시스템 서버를 두고 이렇게 메시지를 보내고(publish) 받는(subscriber) 형태의 통신 형태인 pub/sub 모델의 통신구조입니다. 여기서 미담이지만, 카프카의 창시자인 제이 크렙스는 대학 시절 문학 수업을 들으며 소설가 프란츠 카프카에 심취했습니다. 자신의 팀이 새..
 [주키퍼, Zookeeper] 아파치 주키퍼(Apache Zookeeper) 소개 및 아키텍처
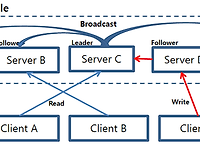
[주키퍼, Zookeeper] 아파치 주키퍼(Apache Zookeeper) 소개 및 아키텍처
| 대규모 분산 시스템과 코디네이션 시스템의 필요성? 과거에는 한 대의 컴퓨터에서 동작하는 단일 프로그램이 대다수였지만, 현재 빅데이터와 클라우드 환경에서 대규모의 시스템들이 동작하고 있습니다. 이 대규모 시스템은 수많은 서버와 인프라로 구성되어 있죠. 또한 이 시스템들은 보통 다양하고 수많은 어플리케이션들로 이루어져 있습니다. 결국 이 개별적인 시스템들을 각각 조율해야하는 코디네이션 시스템의 수요가 생기게 되었습니다. 하지만 이 코디네이션 시스템을 작성하는 것은 아주 까다롭고 복잡한 과정이었습니다. 분산 코디네이션 시스템을 구축하기 위해 들인 노력에 비해 정작 중요한 핵심 로직을 작성하는 시간은 부족하였기 때문에 분산 코디네이션 시스템을 대강 만들게 되거나 아니면 필요한 로직에 집중하지 못하게 된 경우..
 [Zookeeper] Quorum and Majority ( 쿼럼과 과반수 )
[Zookeeper] Quorum and Majority ( 쿼럼과 과반수 )
1. 쿼럼이란 쿼럼은 주키퍼 클러스터인 앙상블을 이루고 있는 모든 서버 중에서, 과반수 서버로 이루어진 그룹을 말합니다. 쿼럼은 반드시 가동되고 있고 클라이언트의 요청을 처리하는 최소한의 서버 노드로 구성되어 있죠. 주키퍼에서 클라이언트에 의해 이루어진 업데이트가 이루어질 시, 반드시 쿼럼의 노드들은 클라이언트의 트랜잭션이 반영된 상태를 유지해야 합니다. 2. 과반수 쿼럼 주키퍼는 앙상블을 구성할 시, 과반수 서버 노드를 채택하여 쿼럼을 구성합니다. 과반수를 채택하는 이유는 분산 코디네이션 환경에서 예상치 못한 장애가 발생해도 분산 시스템의 일관성을 유지시키기 위해서입니다. 만일 과반수로 구성하지 않을 시, 생길 수 있는 문제는 다음과 같습니다. ( 앙상블을 이루는 서버 5대 쿼럼을 이루는 서버 2대라 ..
 [Zookeeper] zoo.cfg 설정값 정보
[Zookeeper] zoo.cfg 설정값 정보
1. 주키퍼 서버 설정 파일 위치 {ZOOKEEPER_HOME}/conf/zoo.cfg 2. 설정 정보 tickTime=2000 dataDir=/var/lib/zookeeper clientPort=2181 initLimit=5 syncLimit=2 server.1=zoo1:2888:3888 server.2=zoo2:2888:3888 server.3=zoo3:2888:3888 tickTime : tick 단위 시간을 설정, milliseconds 단위. 위에서는 2초로 설정됨 dataDir : 주키퍼의 상태, 스냅션, 트랜잭션 로그들을 저장하고 업데이트하는 디렉토리의 위치를 지정 clientPort : 클라이언트 연결을 감지하는 포트의 번호 initLimit : 처음 주키퍼의 follower가 leader..
 [Kafka, 카프카] 아파치 카프카(Apache Kafka) 아키텍처 및 동작방식, 파티션 읽기 쓰기(Partition Read and Write)
[Kafka, 카프카] 아파치 카프카(Apache Kafka) 아키텍처 및 동작방식, 파티션 읽기 쓰기(Partition Read and Write)
| 카프카(Kafka)란? 아파치 카프카(Apache Kafka)는 분산 스트리밍 플랫폼이며 데이터 파이프 라인을 만들 때 주로 사용되는 오픈소스 솔루션입니다. 카프카는 대용량의 실시간 로그처리에 특화되어 있는 솔루션이며 데이터를 유실없이 안전하게 전달하는 것이 주목적인 메세지 시스템에서 Fault-Tolerant한 안정적인 아키텍처와 빠른 퍼포먼스로 데이터를 처리할 수 있습니다. 카프카는 현재 2.x 버전까지 나와있고 초기에 Producer, Consumer 기능에서 0.10.x 버전에서부터 Connectors와 Stream Processors가 추가되었습니다. 이 포스팅에서는 Producer, Consumer에 대해서만 다룰 것이며 카프카가 어떤 아키텍처로 구성되어 있고 어떻게 동작하는 지 간략하게 ..