05 정렬 알고리즘 - 병합 정렬 (Merge Sort)
병합 정렬 (Merge Sort)
전체 원소를 하나의 단위로 분할한 후에 분할한 원소를 다시 병합하며 정렬해 나가는 방식입니다.
■ 정렬 방식
1. 정렬하고자 하는 데이터 집합을 반으로 나눈다.
2. 반으로 나누어진 하위 데이터의 개수가 2이상이면 1의 과정을 반복한다.
3. 같은 집합에서 나온 하위 데이터 둘을 정렬을 시도하면서 다시 병합합니다.
4. 원래의 데이터 집합이 될때까지 3의 과정을 반복합니다.
- 분할과정
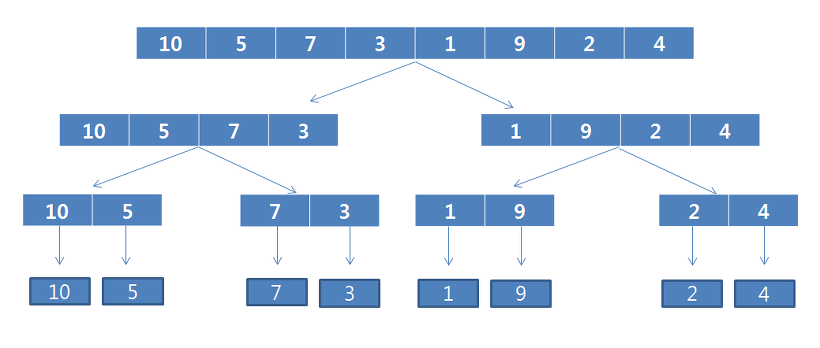
전체 데이터 크기(n=8)에서 반으로(n=4) 나눕니다. 이 과정에 대해서 데이터 집합의 크기가 1이 될 때까지 반복합니다.
-병합과정

같은 집합에서 나온 하위 데이터집합 두개를 정렬과 동시에 병합을 시도합니다. 주목해야 할 점은 병합이 이루어진 데이터 집합에 대해서는 정렬이 이루어졌습니다.
-정렬과정
마지막 하위 데이터에 대해서 어떤 식으로 정렬과 병합이 이루어지는 살펴보겠습니다.

최종 병합만을 놔두고 있는 상태입니다. 앞에 과정도 지금부터 보여주는 방식으로 병합되어 왔다고 생각하시면 됩니다. 먼저 두 개의 집합 데이터(정렬이 되어있음)에 대해서 한 원소씩 가지고 와서 비교를 실시합니다. right의 원소가 left보다 더 작으므로 1이 복사가 됩니다.

현재 1이 복사가 되었고 right의 index는 1이 증가하였습니다. 다시 마찬가지로 비교를 실시를 하는데 right 원소가 더 작으므로 2가 복사가 됩니다.

2가 복사가 되고 right의 index를 1증가시킵니다. 이번엔 left의 원소가 더 작으므로 3을 복사합니다.
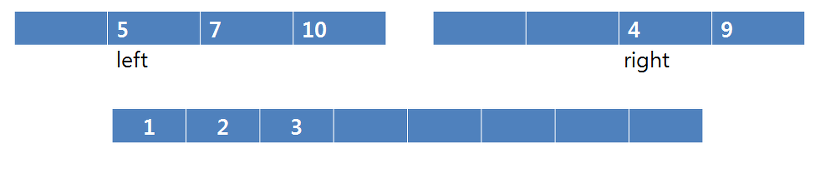
3을 복사하고 left의 index를 1증가시킵니다. 이번엔 right의 원소가 작으므로 4를 복사시킵니다.
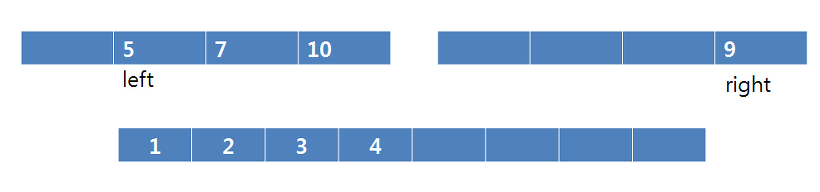
4를 복사하고 right의 index를 1증가시킵니다. 이번엔 left의 원소가 더 작으므로 5를 복사합니다.

5를 복사하고 left의 index를 1증가시킵니다. 이번에도 left의 원소가 더 작으므로 7을 복사합니다.
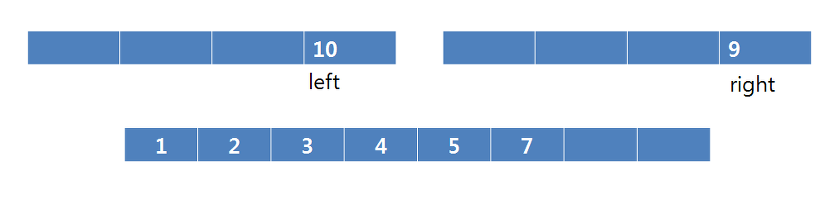
7을 복사하고 left의 index를 1증가시킵니다. 이번에는 right의 원소가 더 작으므로 9를 복사합니다.

9를 복사하고 나면 오른쪽 데이터 집합은 모두 병합이 완료가 되었습니다. 나머지 왼쪽 데이터 집합에 남아 있는 원소를 차례대로 복사를 하면 됩니다.

■ 특징
1. 평균적으로나 최악의 경우에나 O(nlogn)의 복잡도를 갖는다.
2. 정렬을 위해서는 O(n)의 추가적인 공간을 필요로 한다.
출처 : https://lktprogrammer.tistory.com/41?category=672214
'기타 정보 > 알고리즘' 카테고리의 다른 글
| [자바 프로그래밍] 재귀(Recursion) 알고리즘 기초 (0) | 2021.12.13 |
|---|---|
| 07 정렬 알고리즘 - 힙 정렬 (Heap Sort) (0) | 2021.12.13 |
| 06 정렬 알고리즘 - 기수 정렬(Radix Sort) (0) | 2021.12.13 |
| 04 정렬 알고리즘 - 퀵 정렬 (Quick Sort) (0) | 2021.12.13 |
| 03 정렬 알고리즘 - 버블 정렬 (Bubble Sort) (0) | 2021.12.13 |
| 02 정렬 알고리즘 - 삽입 정렬 (Insetion Sort) (0) | 2021.12.13 |
| 01 정렬 알고리즘 - 선택 정렬(Selection Sort) (0) | 2021.12.13 |
| [알고리즘] 분할정복 방법 - 이진 탐색, 퀵 정렬 알고리즘 (0) | 2021.04.21 |