파이썬 재무제표 크롤링: 8개의 글
| 변동하는 코스피(KOSPI), 코스닥(KOSDAQ) 종목 주식 리스트 코스피(KOSPI), 코스닥(KOSDAQ)에 상장된 종목 리스트는 수시로 변합니다. 새로운 기업이 시장에 상장되기도 하면 또한 폐지되기도 하기 때문이죠. 따라서 변동하는 주가 종목들을 갱신하려면 주기적으로 종목 데이터를 업데이트해야 합니다. 이 주식 종목 리스트들을 주기적으로 쉽게 갱신하는 방법 중 하나로 증권사 API를 통해 데이터를 받아오는 방법이 있습니다. | 이베스트 API (Ebest API)를 통한 코스피(KOSPI), 코스닥(KOSDAQ) 종목 요청 이베스트 API를 통해 코스피, 코스닥의 종목 리스트를 쉽게 받을 수 있습니다. 먼저 파이썬을 통해 증권사 API에 로그인한 후 다음과 같은 코드를 실행시킵니다. TR = ..
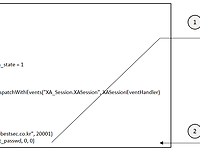 [Python 재무제표 크롤링 #8] 이베스트 API (Ebest API) 접속, 로그인 하기
[Python 재무제표 크롤링 #8] 이베스트 API (Ebest API) 접속, 로그인 하기
| 이베스트 API (Ebest API) 이베스트 API(Ebest API)는 주식 데이터 조회, 주식 주문, 체결 등을 프로그래밍 언어로 제어할 수 있게 해주는 인터페이스입니다.(API에 관한 설명)이 API를 사용하려면 이베스트 증권사의 증권 계정을 만든 후, 이베스트 API를 다운로드 받아서 사용해야 합니다. 아래는 API 다운로드 방법 및 몇 가지 사용 방법을 게시한 사이트입니다. 1. 계좌 개설 및 xingAPI 패키지 설치: 2. 모의투자 가입하기 3. 기초 API 익히기 | 이베스트 API를 통해 로그인 하기 위의 절차를 진행했으면 이제 xingAPI를 통해서 증권 데이터에 접근할 수 있습니다. xingAPI은 이벤트 기반 방식으로 설계되어 있어서 API사용자가 주식 매도,매수 혹은 증권 데..
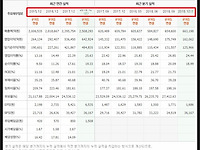 [Python 재무제표 크롤링 #7] NAVER 금융에서 재무제표 데이터, 파이썬 데이터 프레임으로 추출하기
[Python 재무제표 크롤링 #7] NAVER 금융에서 재무제표 데이터, 파이썬 데이터 프레임으로 추출하기
이전 포스팅과 이어지는 내용입니다. [Python/파이썬 재무제표 웹 스크래핑] - [Python 재무제표 크롤링 #6] NAVER 금융에서 재무제표 HTML 요소 추출하기 | 삼성전자 재무제표 부분 HTML 불러오기 삼성전자 재무제표 부분 HTML 를 불러오는 파이썬 스크립트입니다. import requests import numpy as np import pandas as pd from bs4 import BeautifulSoup URL = "https://finance.naver.com/item/main.nhn?code=005930" samsung_electronic = requests.get(URL) html = samsung_electronic.text soup = BeautifulSoup(ht..
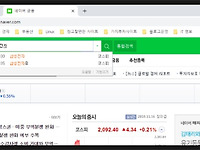 [Python 재무제표 크롤링 #6] NAVER 금융에서 재무제표 HTML 요소 추출하기
[Python 재무제표 크롤링 #6] NAVER 금융에서 재무제표 HTML 요소 추출하기
| NAVER 금융 HTML문서 가져오기 이번 시간에는 우리나라 시가총액 1위인 삼성전자의 재무제표를 크롤링하겠습니다. 먼저 네이버 금융 사이트에 들어갑니다. 네이버 금융의 검색창에서 삼성전자를 검색합니다. 검색한 뒤 삼성전자의 주식정보 페이지에 들어가면 다음과 같은 URL로 검색 되어 있는 것을 볼 수 있습니다. "https://finance.naver.com/item/main.nhn?code=005930" 이 URL을 가지고 현재 사이트의 HTML 문서를 Requests와 BeautifulSoup 라이브러리를 이용해 가져올 것입니다. 다음 코드를 이용해서요 import requests from bs4 import BeautifulSoup URL = "https://finance.naver.com/it..
이전 포스팅과 이어지는 내용입니다. 아래 링크를 참조해 주시기 바랍니다. [Python/파이썬 재무제표 웹 스크래핑] - [Python 재무제표 크롤링 #4] Requests, BeautifulSoup로 크롤링(Crawling), 데이터 추출하기(Data Extraction) - 1 | 시작하기 전에 이번 포스팅에서 사용할 HTML 코드를 받아야합니다. 아래의 python 스크립트를 실행하시면 됩니다. import requests from bs4 import BeautifulSoup page = requests.get("http://dataquestio.github.io/web-scraping-pages/simple.html") soup = BeautifulSoup(page.content, 'html.p..
| Requests, BeautifulSoup 라이브러리 Requests는 웹상의 html문서를 파이썬 언어를 통해 쉽게 사용자 컴퓨터로 가져올 수 있게 하는 라이브러리입니다. 그리고 BeautifulSoup는 가져온 HTML문서를 파싱하여 아주 쉽게 데이터를 추출할 수 있도록 해주는 파이썬 라이브러리입니다. 이 두 라이브러리를 조합하면 특정 웹사이트의 HTML문서를 쉽게 가져와서 데이터를 빠르고 쉽게 추출할 수 있죠. 두 라이브러리는 pip로 쉽게 설치가능합니다. pip install requests pip install BeautifulSoup4 PyCharm을 쓰시는 분들은 해당 라이브러리를 UI로 손쉽게 설치하실 수 있습니다. 설치 방법은 여기를 참조하시면 됩니다. ▶[Python] - [Pyth..
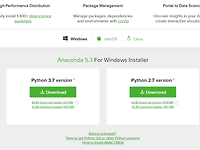 [Python 재무제표 크롤링 #2] Anaconda를 통한 Python 설치하기
[Python 재무제표 크롤링 #2] Anaconda를 통한 Python 설치하기
| Anaconda Anaconda는 구 Continuum Analytics라는 회사에서 ( 현 Anaconda, Inc. )에서 만든 데이터 사이언스와 머신 러닝 어플리케이션을 위한 파이썬 배포판입니다. 현재 1400개 이상의 데이터 사이언스 패키지를 가지고 있어 한 번 설치한다면 따로 package를 설치하는 수고를 하지 않고도 풍부한 라이브러리를 쓸 수 있는 장점이 있습니다. | 설치경로 ▶ https://www.anaconda.com/download/ | 설치방법 사이트에 들어가셔서 위 사이트에서 3.7 version 다운로드 버튼을 누르시면 바로 다운로드가 진행됩니다. 그리고 64bit, 32bit 버전이 둘 다 있는데 맞는 거 쓰시면 됩니다. 저는 32bit 버전으로 진행하도록 하겠습니다. (..
 [Python 재무제표 크롤링 #1] 파이썬 크롤링(Python Crawling)
[Python 재무제표 크롤링 #1] 파이썬 크롤링(Python Crawling)
| Python(파이썬) 파이썬(Python)은 귀도 반 로섬(Guido van Rossum) 네덜란드 아저씨가 만든 인터프리터 언어입니다. 문법이 매우 간결하고 직관적으로 설계되어 있고 거기에 풍부한 라이브러리, 효율적인 자료구조 등 여러 좋은 장점이 많은 언어입니다. Tensorflow같은 인공지능 라이브러리나 나 Numpy같은 수치해석 라이브러리의 힘을 토대로 데이터 사이언스, AI 분야에서 매우 핫한 언어죠. | Web Crawling(웹 크롤링) Web Crawling(웹 크롤링)은 프로그램을 통해 인터넷 상에 있는 웹 페이지들의 데이터들을 추출하는 것을 의미합니다. 방대한 양의 웹 페이지들의 데이터들 프로그램을 통해 긁어모아 원하는 데이터셋을 구축하고 그 데이터셋을 통해 유의미한 정보나 결과를..